David Crane and Eric Pascarello
with Darren James
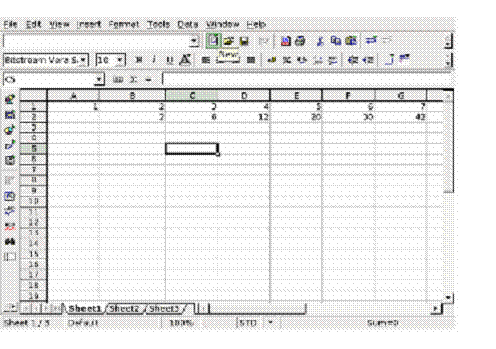
Figure 1.1 This desktop spreadsheet application illustrates a variety of possibilities for user interaction. The headers for the selected rows and columns are highlighted; buttons offer tooltips on mouseover; toolbars contain a variety of rich widget types; and the cells can be interactively inspected and edited.
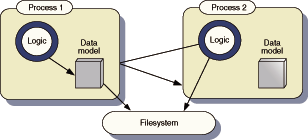
Figure 1.2 Schematic architectures for a standalone desktop application. The application runs in a process of its own, within which the data model and the program logic can ??see?? one another. A second running instance of the application on the same computer has no access to the data model of the first, except via the filesystem. Typically, the entire program state is stored in a single file, which is locked while the application is running, preventing any simultaneous exchange of information.
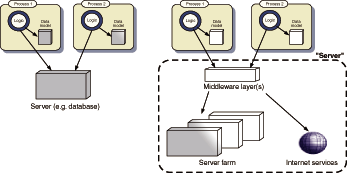
Figure 1.3 Schematic architectures for client/server systems and n-tier architectures. The server offers a shared data model, with which clients can interact. The clients still maintain their own partial data models, for rapid access, but these defer to the server model as the definitive representation of the business domain objects. Several clients can interact with the same server, with locking of resources handled at a fine-grain level of individual objects or database rows. The server may be a single process, as in the traditional client/server model of the early- to mid-1990s, or consist of several middleware tiers, external web services, and so on. In any case, from the client??s perspective, the server has a single entry point and can be considered a black box.
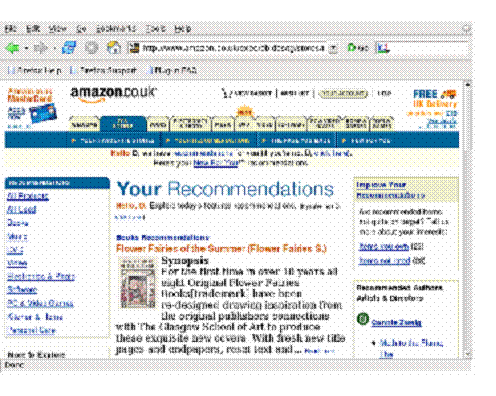
Figure 1.4 Amazon.com home page. The system has remembered who I am from a previous visit, and the navigational links are a mixture of generic boilerplate and personal information.
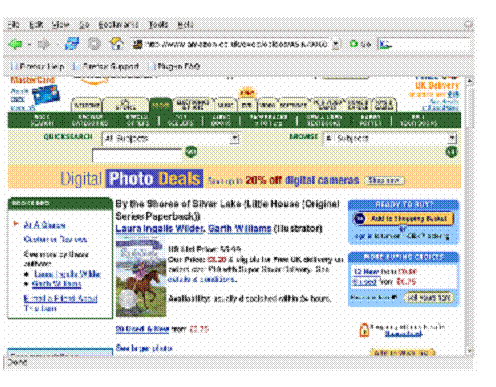
Figure 1.5 Amazon.com book details page. Again, a dense set of hyperlinks combines generic and personal information. Nonetheless, a significant amount of detail is identical to that shown in figure 1.4, which must, owing to the document-based operation of the web browser, be retransmitted with every page.
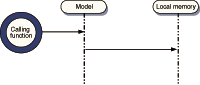
Figure 1.6 Sequence diagram of a local procedure call. Very few actors are involved here, as the program logic and the data model are both stored in local memory and can see each other directly.
with Darren James
reprinted with permission by Manning Publications
Ideally, a user interface (UI) will be invisible to users, providing them with the options they need when they need them but otherwise staying out of their way, leaving users free to focus on the problem at hand. Unfortunately, this is a very hard thing to get right, and we become accustomed, or resigned, to working with suboptimal UIs on a daily basis??until someone shows us a better way, and we realize how frustrating our current method of doing things can be.
The Internet is currently undergoing such a realization, as the basic web browser technologies used to display document content have been pushed beyond the limits of what they can sanely accomplish.
Ajax (Asynchronous JavaScript + XML) is a relatively recent name, coined by Jesse James Garrett of Adaptive Path. Some parts of Ajax have been previously described as Dynamic HTML and remote scripting. Ajax is a snappier name, evoking images of cleaning powder, Dutch football teams, and Greek heroes suffering the throes of madness.
It??s more than just a name, though. There is plenty of excitement surrounding Ajax, and quite a lot to get excited about, from both a technological and a business perspective. Technologically, Ajax gives expression to a lot of unrealized potential in the web browser technologies. Google and a few other major players are using Ajax to raise the expectations of the general public as to what a web application can do.
The classical ??web application?? that we have become used to is beginning to creak under the strain that increasingly sophisticated web-based services are placing on it. A variety of technologies are lining up to fill the gap with richer, smarter, or otherwise improved clients. Ajax is able to deliver this better, smarter richness using only technologies that are already installed on the majority of modern computers.
With Ajax, we are taking a bunch of dusty old technologies and stretching them well beyond their original scope. We need to be able to manage the complexity that we have introduced. This book will discuss the how-tos of the individual technologies but will also look at the bigger picture of managing large Ajax projects. We??ll introduce Ajax design patterns throughout the book as well to help us get this job done. Design patterns help us to capture our knowledge and experience with a technology as we acquire it and to communicate it with others. By introducing regularity to a codebase, they can facilitate creating applications that are easy to modify and extend as requirements change. Design patterns are even a joy to work with!
Why Ajax rich clients?
Building a rich client interface is a bit more complicated than designing a web page. What is the incentive, then, for going this extra mile? What??s the payoff? What is a rich client, anyway?
Two key features characterize a rich client: it??s rich, and it??s a client.
Let me explain a little more. Rich refers here to the interaction model of the client. A rich user interaction model is one that can support a variety of input methods and that responds intuitively and in a timely fashion. We could set a rather unambitious yardstick for this by saying that for user interaction to be rich, it must be as good as the current generation of desktop applications, such as word processors and spreadsheets. Let??s take a look at what that would entail.
1.1.1 Comparing the user experiences
Take a few minutes to play with an application of your choice (other than a web browser), and count the types of user interaction that it offers. Come back here when you??ve finished. I??m going to discuss a spreadsheet as an example shortly, but the points I??ll make are sufficiently generic that anything from a text editor up will do.
Finished? I am. While typing a few simple equations into my spreadsheet, I found that I could interact with it in a number of ways, editing data in situ, navigating the data with keyboard and mouse, and reorganizing data using drag and drop.
As I did these things, the program gave me feedback. The cursor changed shape, buttons lit up as I hovered over them, selected text changed color, highlighted windows and dialogs were represented differently, and so on (figure 1.1).
????
Figure 1.1 This desktop spreadsheet application illustrates a variety of possibilities for user interaction. The headers for the selected rows and columns are highlighted; buttons offer tooltips on mouseover; toolbars contain a variety of rich widget types; and the cells can be interactively inspected and edited.
??
That??s what passes for rich interactivity these days. Arguably there??s still some way to go, but it??s a start.
So is the spreadsheet application a rich client? I would say that it isn??t.
In a spreadsheet or similar desktop application, the logic and the data model are both executed in a closed environment, in which they can see each other very clearly but shut the rest of the world out (figure 1.2). My definition of a client is a program that communicates to a different, independent process, typically running on a server. Traditionally, the server is bigger, stronger, and better than the client, and it stores monstrously huge amounts of information. The client allows end users to view and modify this information, and if several clients are connected to the same server, it allows them to share that data. Figure 1.3 shows a simple schematic of a client/server architecture.
??
Figure 1.2 Schematic architectures for a standalone desktop application. The application runs in a process of its own, within which the data model and the program logic can ??see?? one another. A second running instance of the application on the same computer has no access to the data model of the first, except via the filesystem. Typically, the entire program state is stored in a single file, which is locked while the application is running, preventing any simultaneous exchange of information.
Figure 1.3 Schematic architectures for client/server systems and n-tier architectures. The server offers a shared data model, with which clients can interact. The clients still maintain their own partial data models, for rapid access, but these defer to the server model as the definitive representation of the business domain objects. Several clients can interact with the same server, with locking of resources handled at a fine-grain level of individual objects or database rows. The server may be a single process, as in the traditional client/server model of the early- to mid-1990s, or consist of several middleware tiers, external web services, and so on. In any case, from the client??s perspective, the server has a single entry point and can be considered a black box.
In a modern n-tier architecture, of course, the server will communicate to further back-end servers such as databases, giving rise to middleware layers that act as both client and server. Our Ajax applications typically sit at the end of this chain, acting as client only, so we can treat the entire n-tier system as a single black box labeled ??server?? for the purposes of our current discussion.
My spreadsheet sits on its own little pile of data, stored locally in memory and on the local filesystem. If it is well architected, the coupling between data and presentation may be admirably loose, but I can??t split it across the network or share it as such. And so, for our present purposes, it isn??t a client.
Web browsers are clients, of course, contacting the web servers from which they request pages. The browser has some rich functionality for the purpose of managing the user??s web browsing, such as back buttons, history lists, and tabs for storing several documents. But if we consider the web pages for a particular site as an application, then these generic browser controls are not related to the application any more than the Windows Start menu or window list are related to my spreadsheet.
Let??s have a look at a modern web application. Simply because everyone has heard of it, we??ll pick on Amazon, the bookseller (figure 1.4). I point my browser to the Amazon site, and, because it remembers who I am from my last visit, it shows me a friendly greeting, a list of recommended books, and information about my purchasing history.
??
Figure 1.4 Amazon.com home page. The system has remembered who I am from a previous visit, and the navigational links are a mixture of generic boilerplate and personal information.
??
Clicking on a title from the recommendations list leads me to a separate page (that is, the screen flickers and I lose sight of all the lists that I was viewing a few seconds earlier). This, too, is stuffed full of contextual information: reviews, second-hand prices for the book, links to similar authors, and titles of other books that I??ve recently checked out (figure 1.5).
??
Figure 1.5 Amazon.com book details page. Again, a dense set of hyperlinks combines generic and personal information. Nonetheless, a significant amount of detail is identical to that shown in figure 1.4, which must, owing to the document-based operation of the web browser, be retransmitted with every page.
??
In short, I??m presented with very rich, tightly interwoven information. And yet my only way of interacting with this information is through clicking hyperlinks and filling in text forms. If I fell asleep at the keyboard while browsing the site and awoke the next day, I wouldn??t know that the new Harry Potter book had been released until I refreshed the entire page. I can??t take my lists with me from one page to another, and I can??t resize portions of the document to see several bits of content at once.
This is not to knock Amazon. It??s doing a good job at working within some very tight bounds. But compared to the spreadsheet, the interaction model it relies on is unquestionably limiting.
So why are those limits present in modern web applications? There are sound technical reasons for the current situation, so let??s take a look at them now.
1.1.2 Network latency
The grand vision of the Internet age is that all computers in the world interconnect as one very large computing resource. Remote and local procedure calls become indistinguishable, and issuers are no longer even aware of which physical machine (or machines) they are working on, as they happily compute the folds in their proteins or decode extraterrestrial signals.
Remote and local procedure calls are not the same thing at all, unfortunately.
??Communications over a network are expensive (that is, they are slow and unreliable). When a non-networked piece of code is compiled or interpreted, the various methods and functions are coded as instructions stored in the same local memory as the data on which the methods operate (figure 1.6). Thus, passing data to a method and returning a result is pretty straightforward.
??
Figure 1.6 Sequence diagram of a local procedure call. Very few actors are involved here, as the program logic and the data model are both stored in local memory and can see each other directly.
??